
VITA-1.5: L'AI che Vede, Ascolta e Parla in Tempo Reale
L'interazione tra umani e computer sta per fare un salto di qualità. VITA-1.5, l'ultimo modello sviluppato dai ricercatori di diverse prestigiose istituzioni, promette di rivoluzionare il modo in cui comunichiamo con l'intelligenza artificiale, offrendo un'esperienza multimodale completa e naturale.

Una Rivoluzione nell'Interazione Uomo-Macchina
Fino ad oggi, la maggior parte dei modelli di AI si è concentrata principalmente sull'integrazione di testo e immagini. VITA-1.5 va oltre, aggiungendo una componente fondamentale dell'interazione umana: la voce. Questo nuovo modello non si limita a "vedere" e "leggere", ma può anche ascoltare e rispondere verbalmente, il tutto in tempo quasi reale.
Come Funziona VITA-1.5?
Il sistema si basa su un'architettura innovativa che integra tre componenti principali:
Comprensione Visiva: Utilizza InternViT-300M come encoder visivo, capace di analizzare sia immagini statiche che video. Per le immagini ad alta risoluzione, implementa una strategia di patching dinamico che permette di catturare anche i minimi dettagli.
Elaborazione Audio: Include un encoder audio che processa il parlato attraverso strati di convoluzione e blocchi Transformer, ottimizzati per mantenere alta qualità riducendo al minimo la latenza.
Generazione Vocale: A differenza dei sistemi tradizionali, VITA-1.5 non necessita di moduli esterni per la sintesi vocale, grazie a un decoder audio integrato che permette risposte vocali fluide e naturali.

Un Approccio Graduale all'Apprendimento
Il successo di VITA-1.5 si basa su una metodologia di training in tre fasi:
Training Visione-Linguaggio: Il modello impara prima a comprendere e descrivere immagini e video, sviluppando solide capacità di ragionamento visivo.
Training Audio Input: Viene poi introdotta la comprensione del parlato, permettendo al modello di processare input vocali mantenendo le capacità visive acquisite.
Training Audio Output: Infine, il modello sviluppa la capacità di generare risposte vocali naturali, completando così il ciclo dell'interazione multimodale.
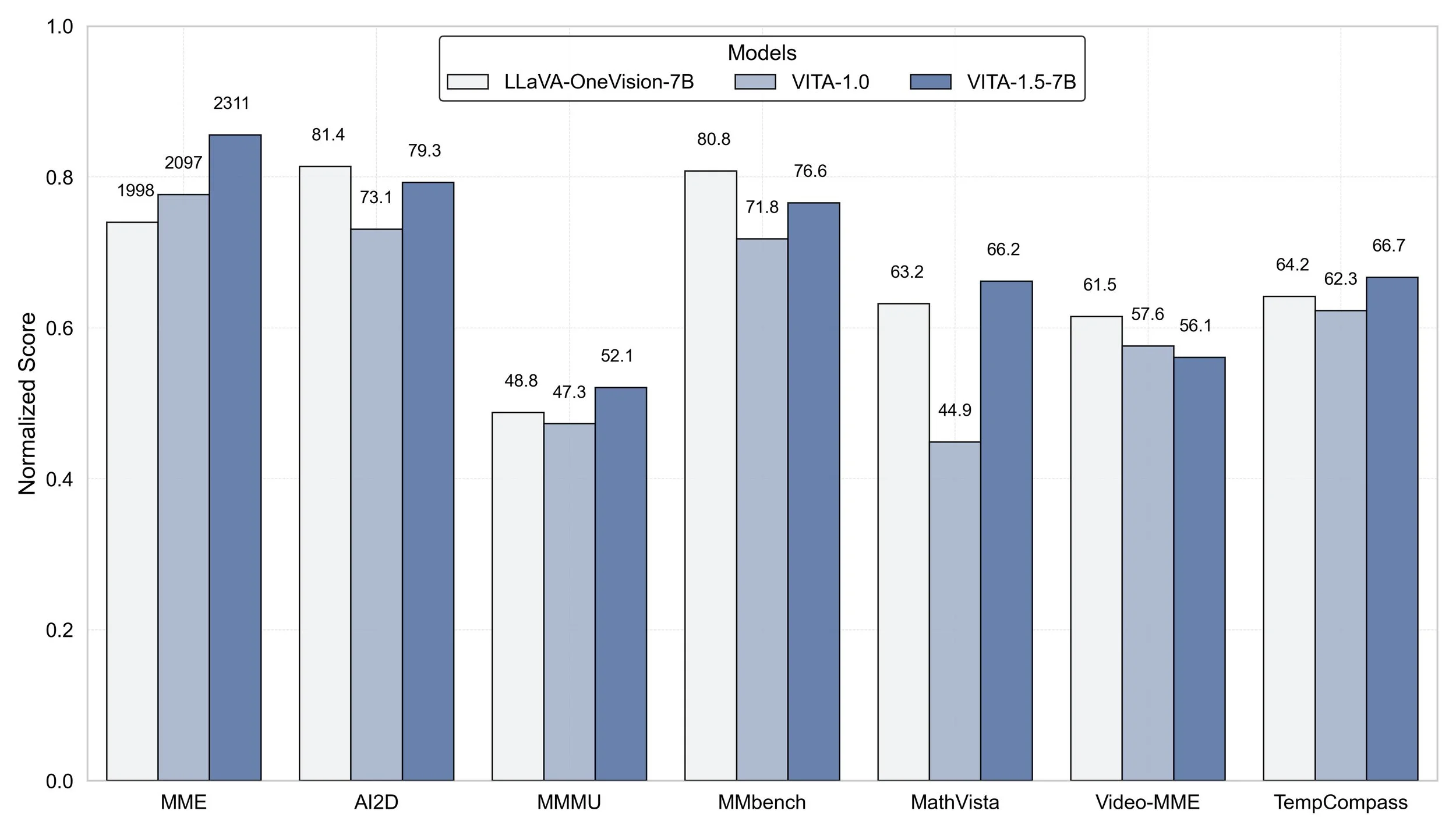
Prestazioni al Top
I risultati dei benchmark sono impressionanti:
Raggiunge performance paragonabili ai migliori modelli open-source nella comprensione di immagini e video
Supera modelli specializzati nel riconoscimento vocale sia in inglese che in mandarino
Mantiene prestazioni elevate anche dopo l'integrazione delle capacità audio, dimostrando l'efficacia della strategia di training graduale
Applicazioni Pratiche
Le potenziali applicazioni di VITA-1.5 sono numerose:
Assistenza Virtuale Avanzata: Interazione naturale e multimodale per supporto clienti o assistenza personale
Accessibilità: Migliore supporto per utenti con diverse esigenze di comunicazione
Educazione: Tutor virtuali capaci di interagire in modo più naturale e coinvolgente
Collaborazione Professionale: Strumenti di comunicazione più ricchi e naturali per team distribuiti
Il Futuro dell'Interazione AI
VITA-1.5 rappresenta un significativo passo avanti verso un'intelligenza artificiale più naturale e accessibile. La capacità di processare e generare contenuti in multiple modalità, mantenendo alta qualità e bassa latenza, apre nuove possibilità per l'integrazione dell'AI in ambiti sempre più diversificati.

Conclusioni
L'introduzione di VITA-1.5 segna un momento importante nell'evoluzione dell'intelligenza artificiale. La sua capacità di integrare visione, linguaggio e audio in un unico sistema efficiente promette di rendere l'interazione con l'AI più naturale e produttiva che mai.
https://arxiv.org/pdf/2501.01957
Se sei interessato a esplorare le potenzialità di VITA-1.5 per il tuo progetto o la tua organizzazione, il codice sorgente è disponibile su GitHub. Contattaci per scoprire come questa tecnologia può trasformare il tuo approccio all'intelligenza artificiale.